Although I benchmarked every revision of Ag, I didn’t profile them all. After looking at the graph in my previous post, I profiled some of the revisions where performance changed significantly.
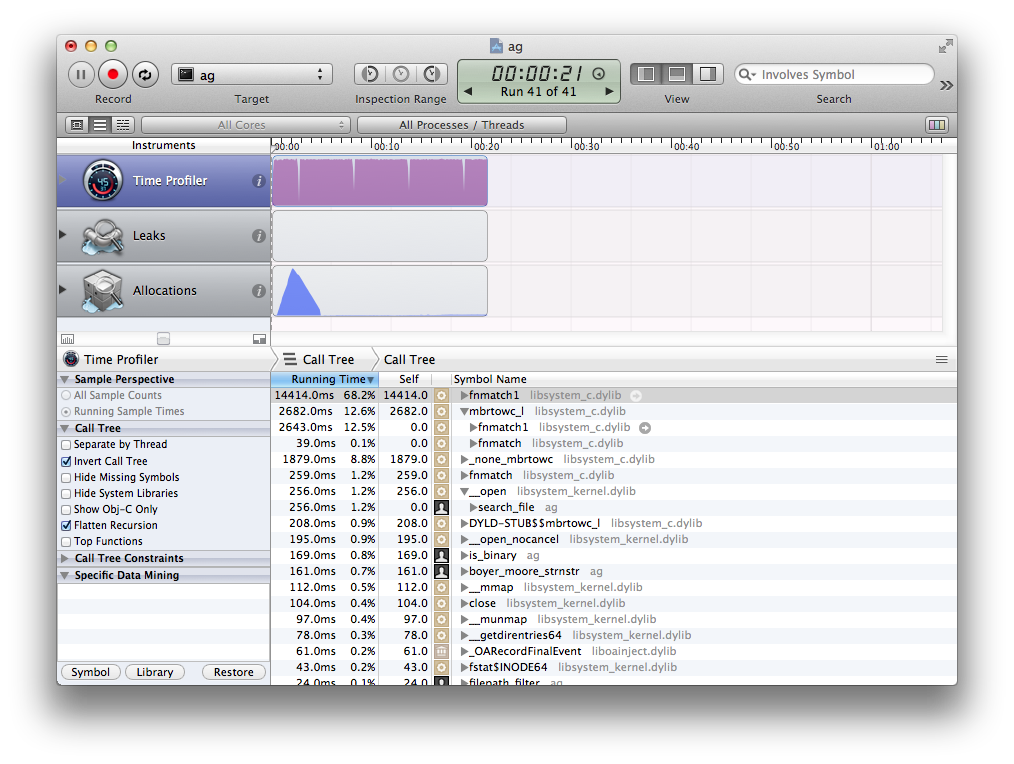 This is a run of revision a87aa8f8; right before I reverted the performance regression. You can see it spends 80% of execution time in
This is a run of revision a87aa8f8; right before I reverted the performance regression. You can see it spends 80% of execution time in fnmatch().
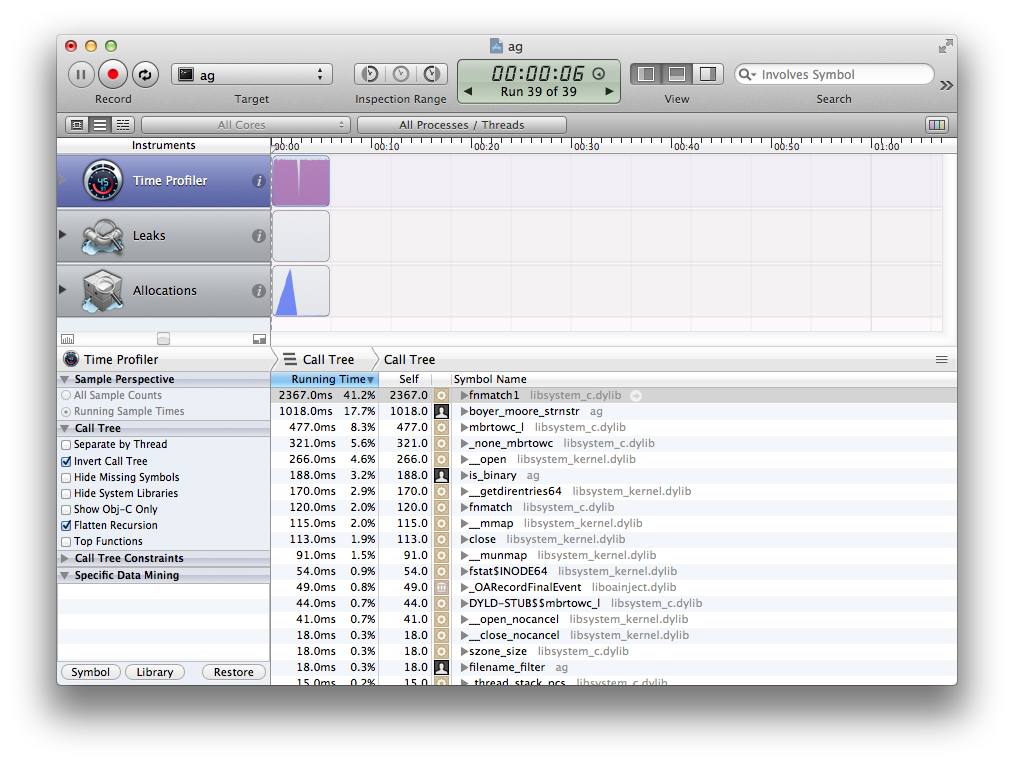 This is tagged release 0.9. Much faster, and it only spends about half the time in
This is tagged release 0.9. Much faster, and it only spends about half the time in fnmatch().
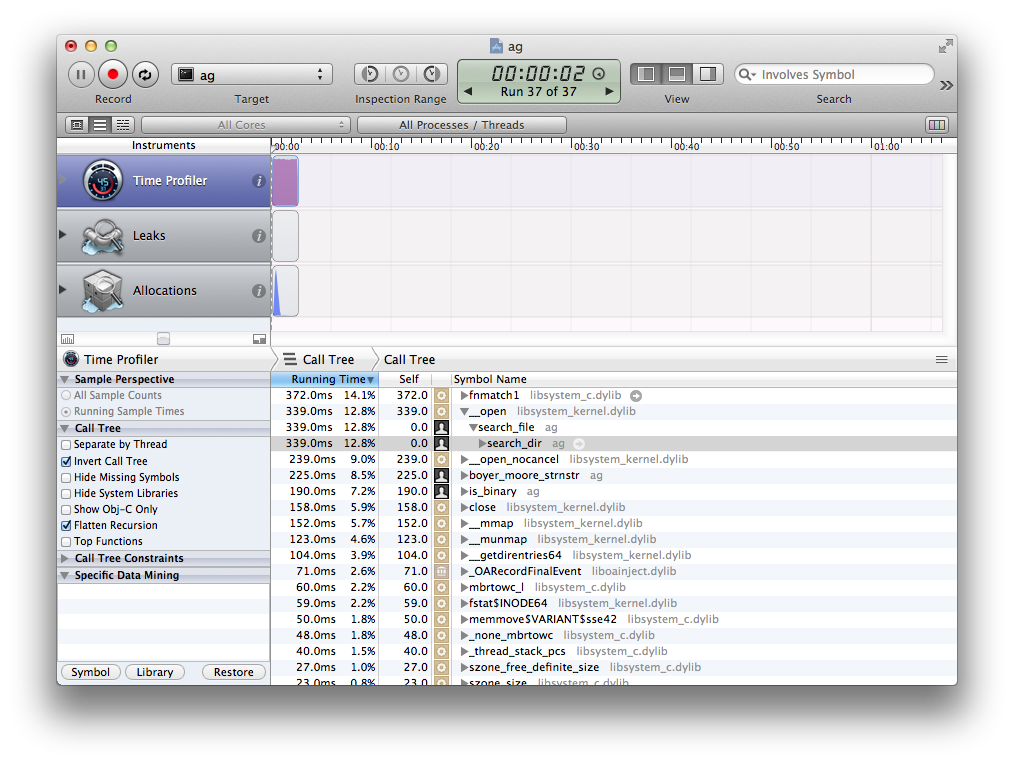 Finally, here’s a run after merging pull request #56. This fixed issue #43 and improved performance for many cases. I’m rather proud of that pull request, since it fixed a lot of issues. The rest of this post explains the specific changes I made to get everything working the way I wanted.
Finally, here’s a run after merging pull request #56. This fixed issue #43 and improved performance for many cases. I’m rather proud of that pull request, since it fixed a lot of issues. The rest of this post explains the specific changes I made to get everything working the way I wanted.
To start with, I should explain Ag’s old behavior. Before I merged that pull request, Ag called scandir() on each directory. Then scandir() called filename_filter() on every entry in the directory. To figure out if a file should be ignored, filename_filter() called fnmatch() on every entry in the global char *ignore_patterns[]. This set-up had several problems:
scandir()didn’t let me pass any useful state tofilename_filter(). The filter could only base its decision on thedirentand any globals.ignore_patternswas just an array of strings. It couldn’t keep track of a hierarchy of ignore files in subdirectories. This made some ignore entries behave incorrectly (issue #43). This also hurt performance.
Fixing these issues required rejiggering some things. First, I wrote my own scandir(). The most important difference is that my version lets you pass a pointer to the filter function. This pointer could be to say… a struct containing a hierarchy of ignore patterns.
Surprise surprise, the next thing I did was make a struct for ignore patterns:
struct ignores {
char **names; /* Non-regex ignore lines. Sorted so we can binary search them. */
size_t names_len;
char **regexes; /* For patterns that need fnmatch */
size_t regexes_len;
struct ignores *parent;
};This is sort of an unusual structure. Parents don’t have pointers to their children, but they don’t need to. I simply allocate the ignore struct, search the directory, then free the struct. This is done around line 340 of search.c. Searching is recursive, so children are freed before their parents.
The final change was to rewrite filename_filter(). It calls fnmatch() on every entry in the ignore struct passed to it. If none of those match and ig->parent isn’t NULL, it repeats the process with the parent ignore struct, and so-on until it reaches the top.
All-in-all, not a bad change-set. I fixed a lot of things I’d been meaning to fix for a while. I also managed to clean up quite a bit of code. If not for my re-implementation of scandir(), the pull request would have removed more lines than it added.
One last thing: I’d like to praise a piece of software and criticize another. I tip my hat to Instruments.app. I’ve found it invaluable for finding the causes of many memory leaks and performance issues. But I wag my finger at git. Git allows .gitignore files in any directory, and it allows these files to contain regular expressions. Worse, these regexes can reference sub-directories. For example, foo/*/bar is a valid ignore pattern. Regular expressions plus directory hierarchies translate to complicated implementations and confusing behavior for users. It’s no fun for anyone involved.