In my quest to improve Ag’s speed, I spent some time making it multi-threaded. This meant learning Pthreads.
Although the Pthreads API wasn’t too hard to pick up, other architectural decisions took more effort to get right. My first attempt at multithreaded search was rather naïve. The plan was simple: For each file, create a new thread, search the file, then exit the thread. It didn’t require a huge change in the code, but I wasn’t sure what kind of performance benefit I’d get. A typical run of Ag searches a lot of files, and spawning a thread for each file could incur some significant overhead. Still, I figured it was worth a shot. It wasn’t long before I had things working, but my initial results were discouraging:
% time ./ag blahblahblah ~/code
...
./ag blahblahblah ~/code 2.18s user 20.91s system 152% cpu 15.134 total
%15 seconds. That’s 7x slower than non-threaded Ag! I broke out the profiler.
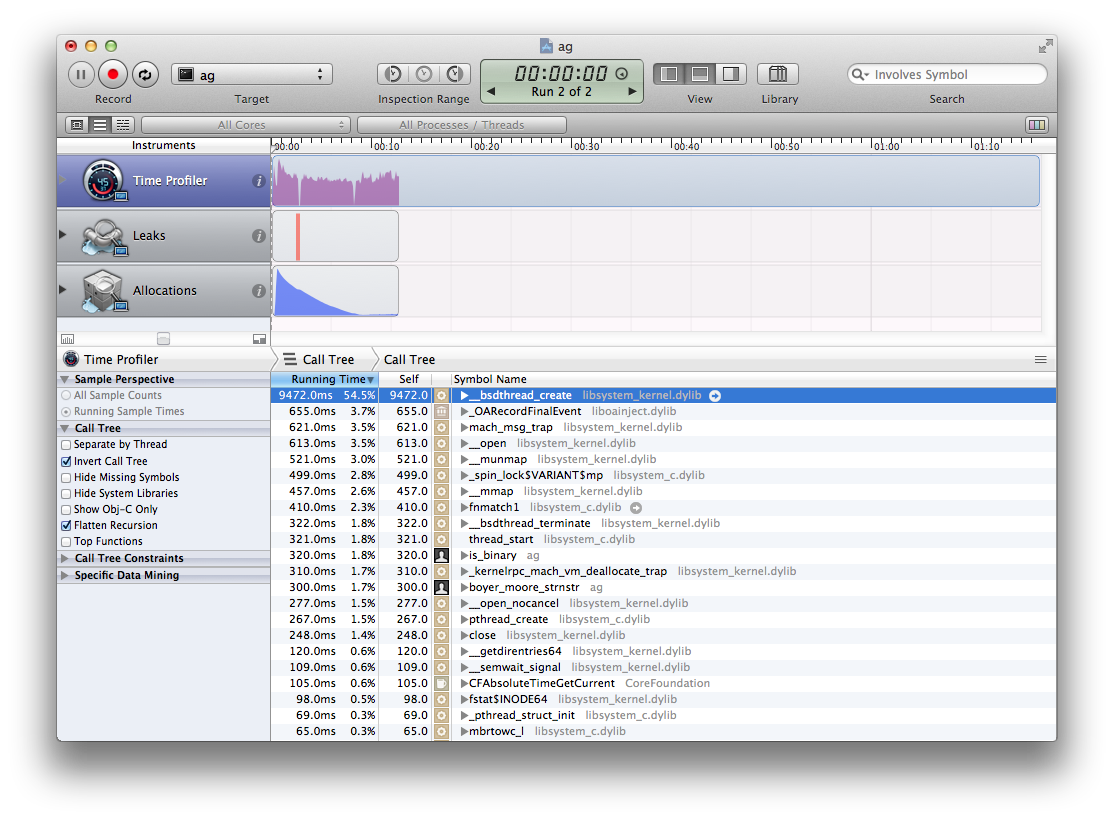
Creating a new thread isn’t free. I knew there was overhead, but now I knew how much. Apparently, it’s not very efficient to search 60,000 files by creating and destroying 60,000 threads.
Next, I tried a different concurrency pattern: Worker threads. I changed search_dir() so that instead of calling search_file() on a path, it added paths to a work queue. At the same time, worker threads grabbed paths off the queue and called search_file() on them. I had to use a couple of mutexes to avoid some race conditions, but it was surprisingly easy to get correct behavior.
Once I was ready, I re-ran my benchmark:
% time ./ag blahblahblah ~/code
...
./ag blahblahblah ~/code 1.47s user 2.54s system 231% cpu 1.731 total
%Much better, but it was only 0.3 seconds faster than non-threaded Ag. Searching files is embarrassingly parallel. I expected more than a 15% performance improvement.
So I started tweaking things. Most changes didn’t help, but performance was significantly affected by the number of worker threads. I assumed 3-4 workers would be ideal, but I ran benchmarks with up to 32 threads just to make sure. I graphed the results. For comparison: non-threaded Ag takes 2.0 seconds on my MacBook Air and 2.2 seconds on my Ubuntu server.
There are a couple of takeaways from this graph.
First, OS X sucks at this benchmark. With 16 workers, performance is pitiful. I had to remove the 32-worker results from the graph, as they made it hard to see the difference in performance with fewer threads. Searching with 32 workers took 8.5 seconds on OS X. That’s just shameful. On the other hand, the Linux kernel seems to get things right. Even with 32 workers, it took 2.2 seconds.
Again, I pulled out the profiler. With 32 workers, Ag looks like this on OS X:
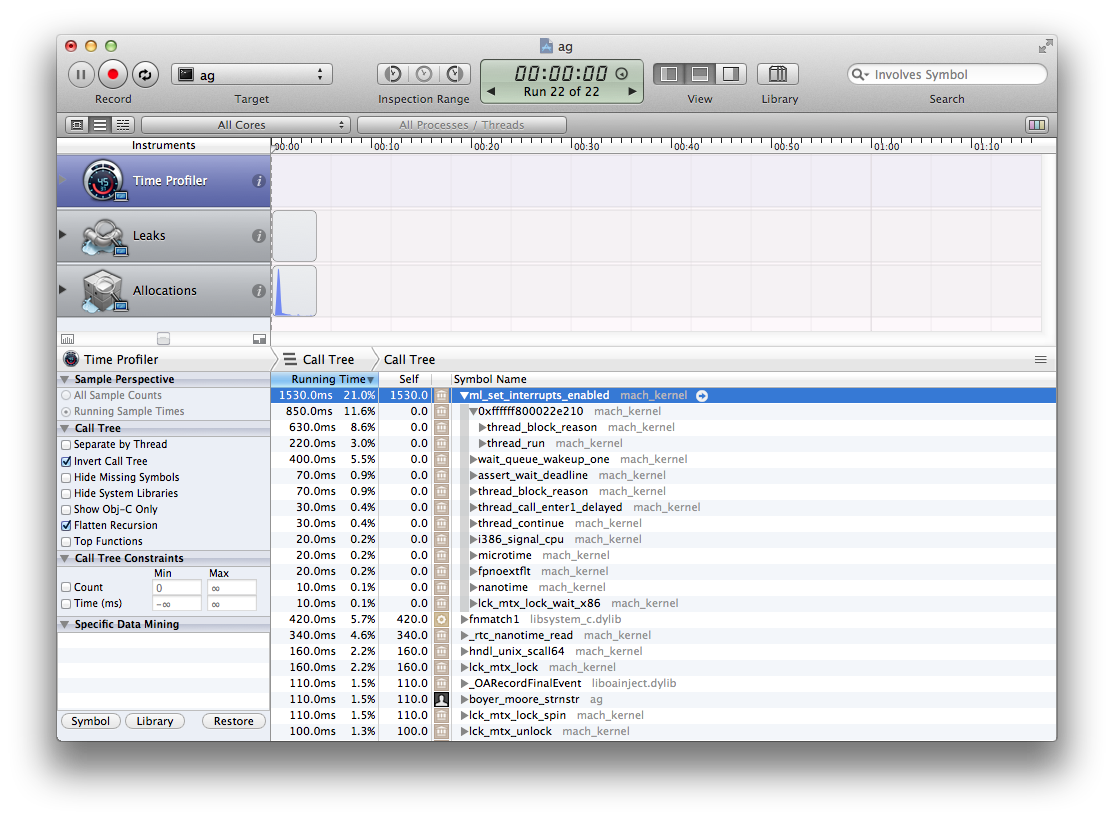
There’s definitely some silliness going on in the kernel.
Anyway, getting back to the graph up above: The second thing I learned was that the optimal number of worker threads doesn’t correlate with CPU cores. Even on a quad-core CPU, performance was best with two workers. I want to figure out why this is the case, but for now I’m simply going to accept it and tweak Ag for performance. My guess is that the bottleneck is no longer the CPU. The new limiting factor could be memory bandwidth or latency.
After tweaking the worker thread count, I think I’m getting pretty close to the maximum possible searching speed. Take a look at the current profiling info:
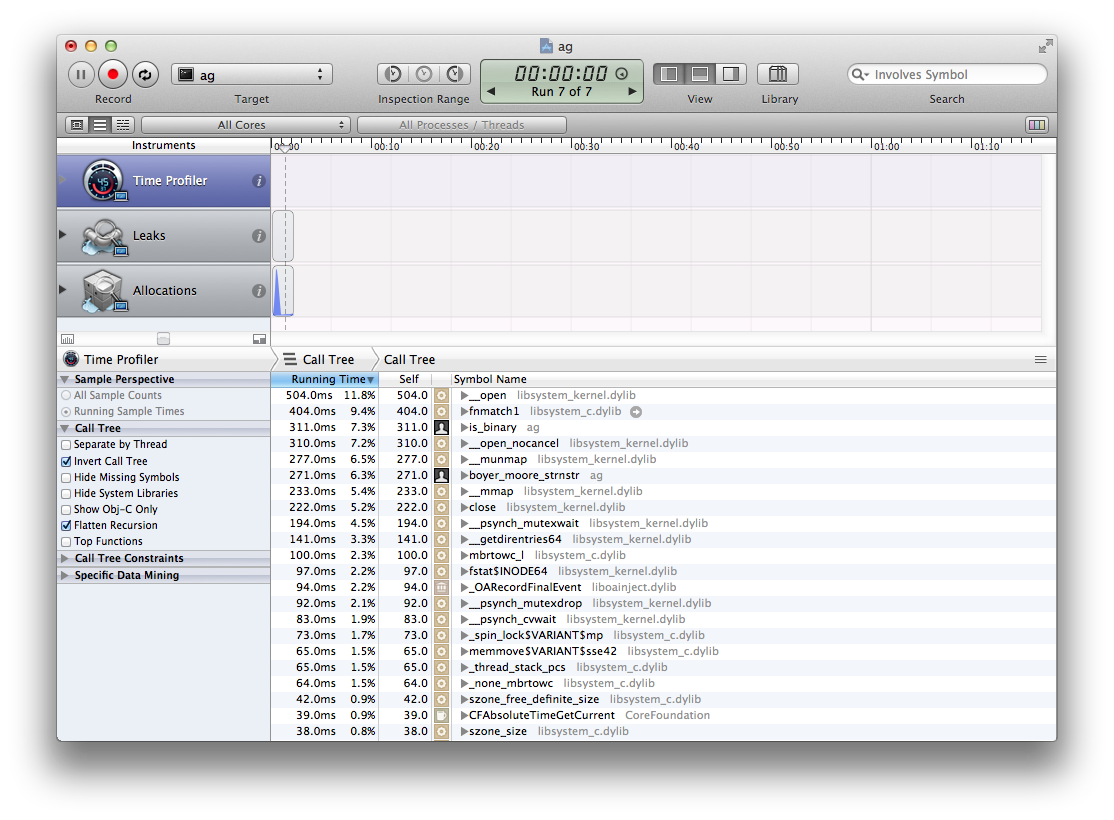
There’s no obvious bottleneck. All the time is spent doing things that simply must be done: open files, read data, match, close files. Another indication that I can’t make things much faster is this:
% time du -sh ~/code
5.8G /Users/ggreer/code
du -sh ~/code 0.09s user 1.42s system 95% cpu 1.572 total
%That’s right, my benchmark data set is 5.8 gigabytes. Ag doesn’t actually search through the whole 5.8 gigabytes in 1.4 seconds. The total amount of data searched is around 400MB. Still, I’m surprised Ag is faster than du.
It looks like this project is starting to wrap up. Now that I’ve maxed-out performance, most changes should be feature requests and bug fixes. That said, it’s been a fun journey. I learned a lot of things about a lot of things.